

Imagens Getty
No mundo da inteligência artificial, o que poderia ser chamado de “modelos de microlinguagem” aumentou recentemente em popularidade porque podem ser executados em uma máquina local, em vez de precisarem de computadores no nível do data center na nuvem. Quarta-feira da maçã pé Um conjunto de pequenos modelos de linguagem de IA disponíveis publicamente, chamados OpenELM, que são pequenos o suficiente para serem executados diretamente em um smartphone. No momento, eles são principalmente modelos de pesquisa de prova de conceito, mas podem formar a base para futuras ofertas de IA em dispositivos da Apple.
Os novos modelos de IA da Apple, chamados coletivamente de OpenELM (Open Source Efficient Language Models), estão atualmente disponíveis em Abraço facial sob Licença de exemplo de código Apple. Devido a algumas restrições na licença, pode não ser compatível com Definição geralmente aceita “Código aberto”, mas o código-fonte do OpenELM está disponível.
Na terça-feira, cobrimos os modelos Phi-3 da Microsoft, que visam alcançar algo semelhante: um nível útil de compreensão de linguagem e desempenho de processamento em pequenos modelos de IA que podem ser executados localmente. O Phi-3-mini possui 3,8 bilhões de parâmetros, mas alguns modelos OpenELM da Apple são muito menores, variando de 270 milhões a 3 bilhões de parâmetros em oito modelos distintos.
Em comparação, o maior modelo lançado até agora na família Llama 3 da Meta inclui 70 bilhões de parâmetros (com um lançamento de 400 bilhões a caminho), e o GPT-3 da OpenAI de 2020 foi enviado com 175 bilhões de parâmetros. O número de parâmetros é uma medida aproximada do poder e da complexidade de um modelo de IA, mas pesquisas recentes têm se concentrado em tornar modelos menores de linguagem de IA tão capazes quanto os maiores que eram há alguns anos.
Os oito modelos OpenELM vêm em duas versões: quatro “pré-treinados” (essencialmente uma versão inicial do próximo modelo) e quatro ajustados por instrução (ajustados para seguir instruções, mais ideais para desenvolver assistentes de IA e chatbots):
OpenELM apresenta uma janela de contexto com no máximo 2.048 tokens. Os modelos foram treinados em conjuntos de dados disponíveis publicamente RefinadoWebUma cópia de pilha Com as duplicatas removidas, um subconjunto de Pijama vermelhoe um subconjunto de Dolma v1.6, que a Apple diz totalizar cerca de 1,8 trilhão de tokens de dados. Tokens são representações segmentadas de dados que os modelos de linguagem de IA usam para processamento.
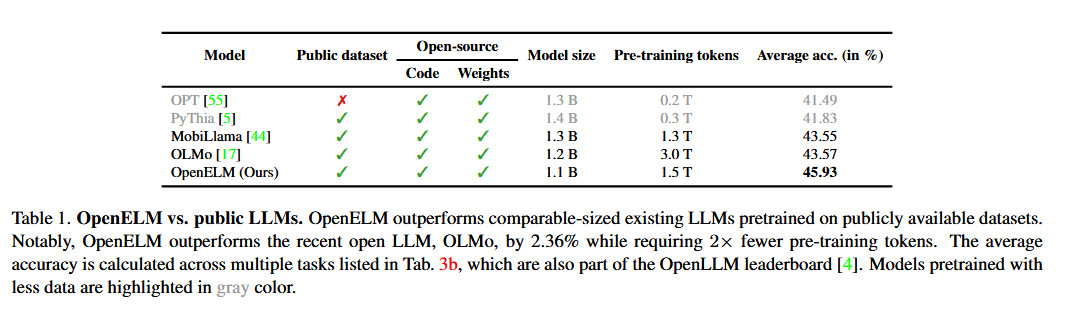
A Apple afirma que sua abordagem com OpenELM inclui uma “estratégia de escalonamento de camada” que aloca parâmetros de forma mais eficiente em cada camada, não apenas economizando recursos computacionais, mas também melhorando o desempenho do modelo à medida que ele treina com menos tokens. De acordo com o que foi divulgado pela Apple Livros brancosEsta estratégia permitiu que o OpenELM alcançasse uma melhoria de 2,36% na precisão em comparação com os sistemas Allen AI Olmo 1b (outro modelo de linguagem pequena), exigindo metade do número de tokens para pré-treinamento.
maçã
A Apple também lançou o código para rede principal, uma biblioteca que usei para treinar o OpenELM, também incluía receitas de treinamento repetíveis que permitem a repetição de pesos (arquivos de rede neural), o que é incomum para uma grande empresa de tecnologia até agora. Como afirma a Apple em seu resumo de pesquisa OpenELM, a transparência é um objetivo fundamental para a empresa: “A reprodutibilidade e a transparência de grandes modelos de linguagem são essenciais para promover pesquisas abertas, garantir a confiabilidade dos resultados e permitir investigações sobre dados e preconceitos de modelos, como bem como riscos potenciais.
Ao divulgar o código-fonte, os pesos dos modelos e os materiais de treinamento, a Apple afirma que pretende “capacitar e enriquecer a comunidade de pesquisa aberta”. No entanto, também alerta que, uma vez que os modelos são treinados em conjuntos de dados de origem pública, “existe a possibilidade de que estes modelos possam produzir resultados imprecisos, prejudiciais, tendenciosos ou questionáveis em resposta às solicitações dos utilizadores”.
Embora a Apple ainda não tenha integrado esta nova onda de recursos de modelo de linguagem de IA em seus dispositivos de consumo, há rumores de que a próxima atualização do iOS 18 (que deverá ser revelada em junho na WWDC) incluirá novos recursos de IA que usam processamento em movimento. Dispositivo para garantir o usuário. Privacidade – Embora seja provável que a empresa contrate o Google ou a OpenAI para lidar com o processamento mais complexo de IA fora do dispositivo para dar ao Siri um impulso há muito esperado.

“Estudante amigável. Jogador certificado. Evangelista de mídia social. Fanático pela Internet. Cai muito. Futuro ídolo adolescente.”